Cet article explique comment importer et exporter des fichiers audio (au format wav) dans LTspice.
Cela est très intéressant pour tester un effet analogique et simuler par exemple le rendu d’une pédale de guitare!
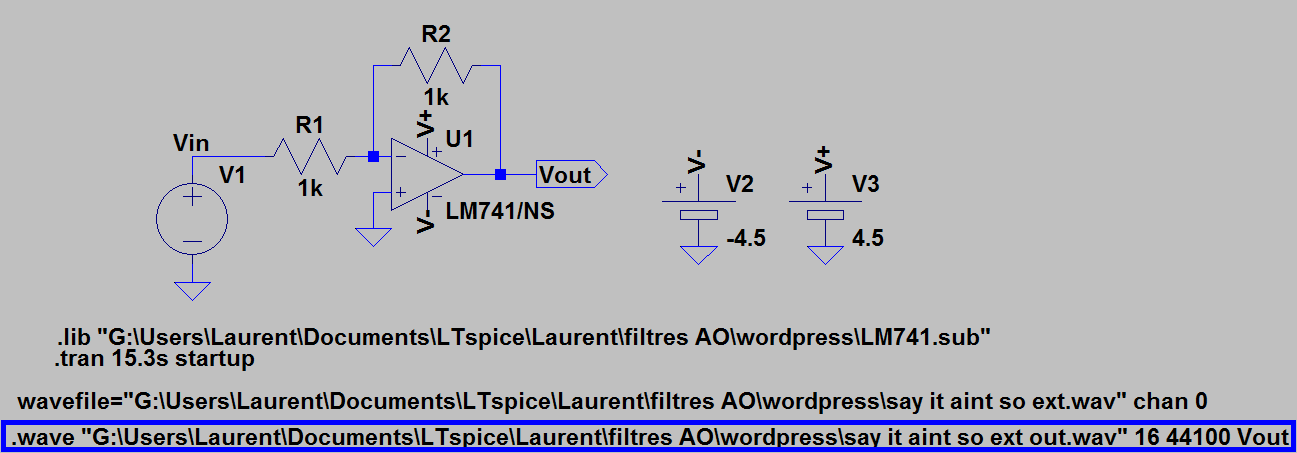
Commençons par un montage de base avec un AO:

C’est un amplificateur inverseur. Comme R1 = R2, c’est un inverseur simple.
L’AMPLIFICATEUR OPERATIONNEL
Pour l’ampli op, on a choisi un ampli op standard LM741.
Je passe rapidement sur les détails techniques : on utilise le fichier LM741.sub et on ajoute la directive
« .lib C:\monchemin\LM741.sub »
On renomme opamp2 en LM741/NS.
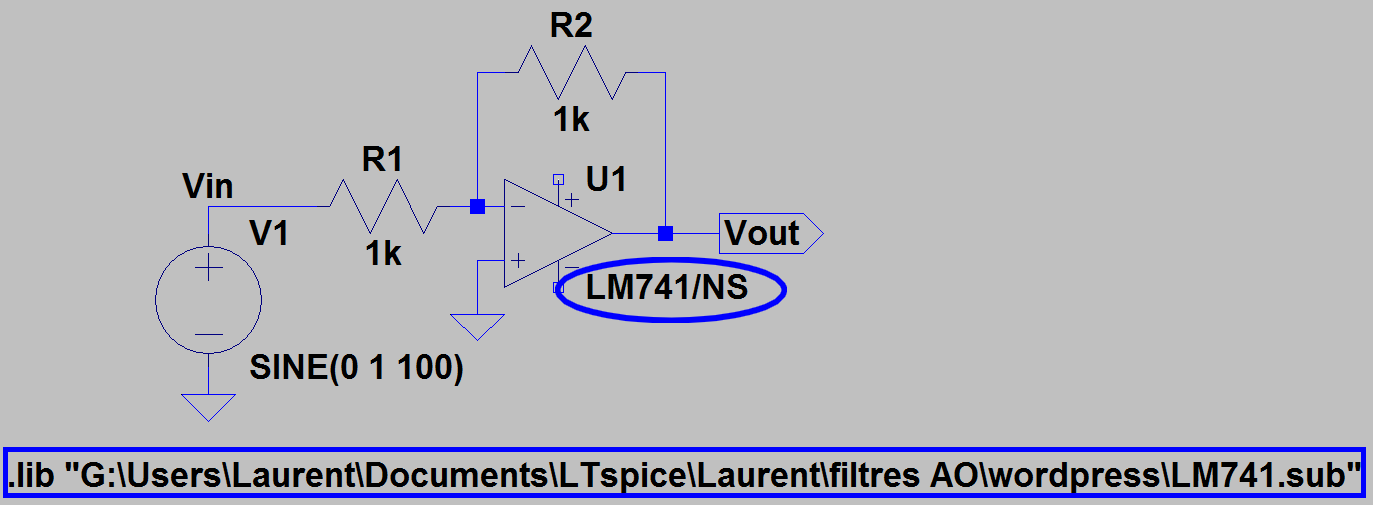
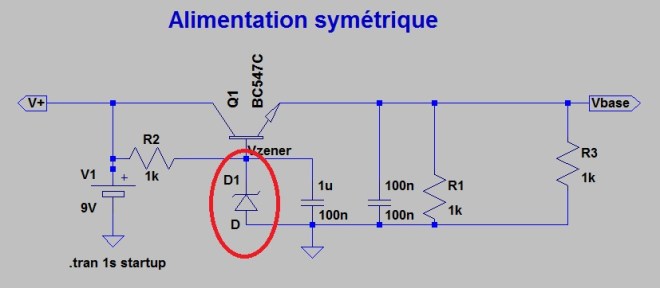
Il reste à ajouter une alimentation symétrique en -4.5v, +4.5V pour alimenter l’AO. On utilise pour cela deux « cells » avec les labels V+ et V- :
Ci-joint le circuit inverseur.
AJOUT D’UN FICHIER AUDIO EN ENTREE
Le « trick », c’est de presser la touche « ctrl » tout en cliquant droit sur le générateur de tension (le composant « voltage »):
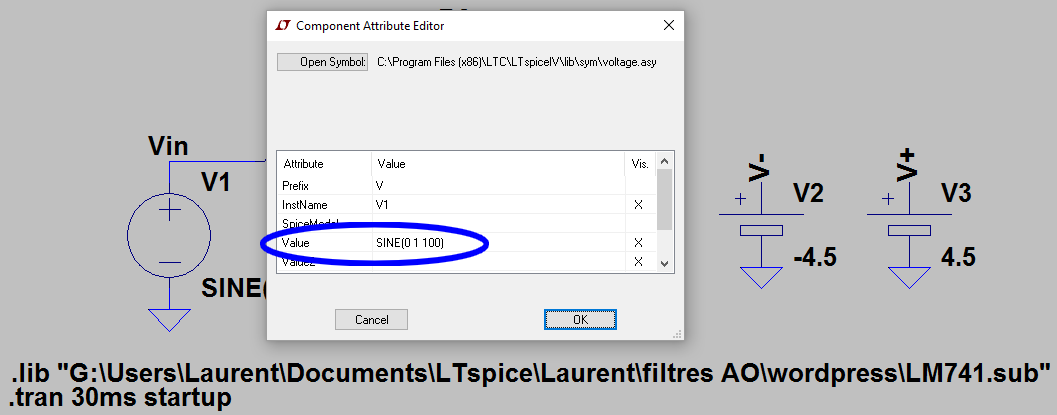
Dans le champ « value », on utilise le mot clef wavefile
wavefile= »C:\monchemin\monfichier.wav » chan 0
chan 0 indique de prendre le premier canal, en cas de fichier stéréo.

Ci-joint le fichier audio (enregistré avec un smartphone de base) : say it aint so extrait . Ce fichier dure environ 15.2 secondes. Dans la « simulation command », on ajuste la durée à 15.3 secondes.
ENREGISTREMENT DU FICHIER AUDIO EN SORTIE
On ajoute pour cela une directive avec le mot clef .wave :
.wave « C:\monchemin\monfichierWavOut.wav » 16 44100 Vout
- .wave : pour indiquer que la sortie est un audio au format wav,
- « C:\… » : le nom du fichier de sortie,
- 16 : nombre de bits de quantification – 16 bits est la valeur standard,
- 44100 : fréquence d’échantillonnage en Hz, c’est à dire le nombre de valeurs par seconde. 44100, c’est la qualité CD,
- Enfin, Vout est le label qui correspond à la sortie.

SIMULATION D’UN EFFET PASSE-BAS
Pour que cela devienne intéressant, on transforme notre circuit inverseur en un passe-bas par l’ajout d’une capa en parallèle de la résistance R2.
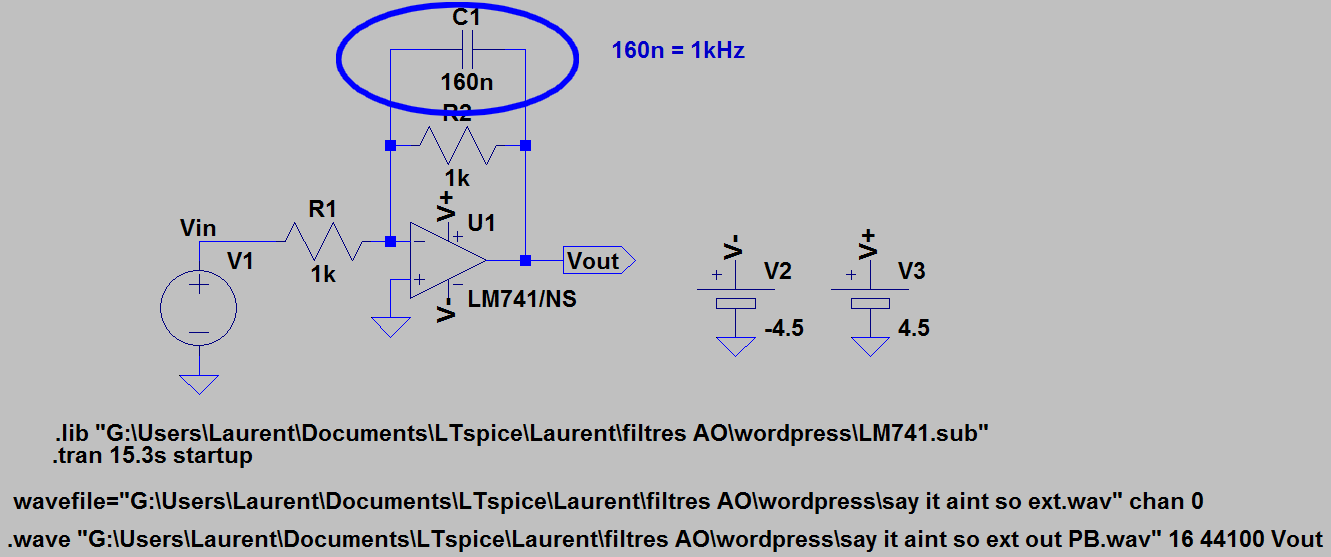
La fréquence de coupure du passe-bas est 1/(2*pi*R2*C1). Avec C1=160n, cette fréquence est d’environ 1kHz.
On lance la simulation. Notez bien que la simulation demande une latence considérable. Il est conseillé de tester son circuit sur des fichiers courts.
Ci-joint, le fichier audio en sortie du passe-bas : say it aint so extrait passe base 1kHz .
CONCLUSION
L’audio en entrée et en sortie, la possibilité de simuler des effets analogiques. Rien à dire : LT spice c’est génial!
P.J. : le schéma spice pour le passe-bas avec audio en entrée et sortie : PB