Dans ce post, je vais expliquer comment retirer la musique de la parole, dans l’audio généré dans la démo de Acapela. Nous allons enregistrer le flux audio généré avec Audacity et en utiliser un programme home-made en python pour la séparation parole/musique.
Acapela permet faire de la synthèse de la parole à partir du texte ou encore TTS – Text To Speech. Il y a plein de voix possible et le truc marche super bien.
Acapela propose une version de démonstration avec une limite de temps sur l’audio généré et avec la musique ajoutée à la parole.
Pour sauvegarder la parole et retirer la musique de fond, il va falloir :
- entrer une phrase dans le TTS dans Acapela demos.
- enregistrer le flux audio avec Audacity et générer la phrase
- sauvegarder l’audio dans Audacity en faisant attention de le mettre en 22050 Hz.
- télécharger l’application appcapela qui est une interface graphique (GUI) en python 3, qui va permettre de séparer la parole de la musique.
On va enregistrer un flux audio avec Audacity. Ceci est détaillé dans l’article Enregistrer vos flux audio avec Audacity sous Windows Il faut:
- taper « peripherique » dans la case en bas à gauche de Windows, choisir « gérer les périphériques audio ». Dans l’onglet « enregistrement », cliquez droit sur « mixage stéréo » et puis « activer » et « définir comme périphérique par défaut ».

- lancer Audacity, changer les options d’enregistrement:

- sélectionner « Windows WASAPI »
- à côté du microphone choisir « xxx (loopback) ». Dans mon cas, c’est « OUT (UA – 25EX (loopback) » parce que j’ai une carte son USB UA-25EX. L’important, c’est « loopback » qui permet de récupérer le flux audio.
- Choisir « 1 (Mono) Recording Channel », pour enregistrer en mono.
- Important, choisir une fréquence d’échantillonnage de 22050 Hz!
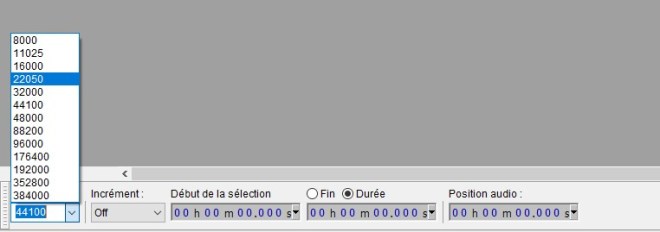
On peut toujours ré-échantillonner avec ffmpeg, avec la commande
« ffmpeg -i monfichier.wav -ar 22050 monfichier_22050.wav ».
Je ferai peut-être un post sur l’utilisation de ffmpeg sous Unix et sous Windows (plus tricky). - Lancer l’enregistrement (bouton rouge en haut)
- Lancer le flux à enregistrer, comme YouTube par exemple. Dans notre cas, ce sera la démo de Acapela.
- Stopper l’enregistrement
- Nettoyer l’enregistrement avec l’outil ciseau
- Enfin exporter l’audio.

Installer python/ Anaconda3
Le programme permettant de séparer la voix de la musique est écrit en Python. Il va donc falloir installer Python (version 3.x) avec Anaconda. Télécharger aussi le programme qui se trouve dans « GitHub ».
- télécharger Anaconda3 et l’installer.
Anaconda pour Python 3 - La version 3.7 de Python s’avère être incompatible avec le paquet « wxpython-phoenix » qui se charge de l’interface graphique. On va donc créer un environnement virtuel pour python 3.6. C’est la bonne manière de procéder. Pour cela, on ouvre une fenêtre DOS en tapant « cmd » en bas à gauche de l’écran Windows (là où il y est écrit « Tapez ici pour rechercher »), puis entrée/return.
Dans la fenêtre de commande, tapez conda create –name py36 python=3.6 anaconda (création de l’environnement) - activer l’environnement en tapant « activate py36 » dans la fenêtre de commande. Sous Linux ou Mac Os, ce serait « source activate py36 ».
- Télécharger appcapela
Aller dans mon repo « LaurentNorbert » dans GitHub : appcapela et télécharger :
puis décompresser l’archive. - Pour lancer appcapela :
- lancer la fenêtre de commande en tapant « cmd » en bas à gauche dans la barre Windows et taper entrer/return pour la lancer.
- si c’est une nouvelle fenêtre de commande, tapez « activate py36 ».
- installer les paquets en ligne de commande en tapant:
- conda install -c newville wxpython-phoenix
- pip install resampy
- pip install soundfile
- aller dans le répertoire dans lequel on a décompressé l’archive. Si le répertoire est « C:\Users\laure\Downloads\appcapela-master\appcapela-master », alors tapez « cd C:\Users\laure\Downloads\appcapela-master\appcapela-master ».
- taper « pythonw appcappella.py » pour lancer l’application.
Attention il faut utiliser pythonw et non python, parce que c’est une application graphique (GUI).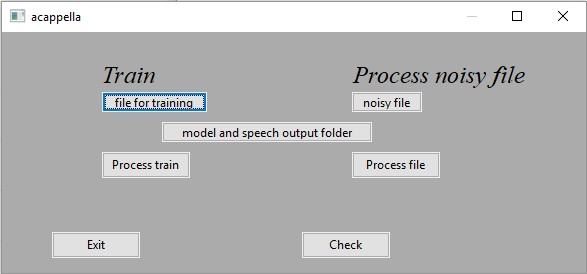
- Dans l’interface graphique :
- cliquez sur le bouton « model and speech output folder » et sélectionnez le répertoire outputandmodel.
- cliquez sur le bouton « noisy file » et choisissez le fichier audio que vous souhaitez dé-bruiter.
- cliquez sur « process file », attendez qu’un popup vous indique que le traitement est terminé.
- le fichier traité se trouve dans le répertoire outputandmodel
DONE !!!!
